
職場で SRE 本の輪読会をしている。職場の Qiita::Team でサマリをまとめて、輪読会仲間にシェアしたのだけれど、別にこの内容は一般に公開してもかまわないものなので、ブログ記事にしてみた。
以下で括弧書きされているものは、注釈と僕の心の声とが半々である。また、本記事の画像は上記の SRE 本からの引用である。
Chapter 8. Release Engineering
Google ではリリースに対して責任を持つ Release Engineering という仕事がある。そういう職種もある。
The Role of a Release Engineer
- コードが変更されてからリリースされるまでの時間を測っていたりする。
- この時間を release velocity と呼ぶ。
- リリースエンジニアはリリースに必要なツールを作る。
- リリースエンジニアはリリースのベストプラクティスを作る。
- 一貫性のあるプラクティス
- 繰り返しデプロイできるプラクティス。
(リリースエンジニアと SRE が協調して働く… みたいな記述があるので、これは SRE とは別な Role なのかな 🤔)
Philosophy
リリースエンジニアの哲学には4つの原則がある。
Self-Service Model
各々のチームがどのくらいの頻度でいつリリースするか自分で決められる。リリース/デプロイツールで、人手を極力排してリリースできるようにする。
High Velocity
少ない変更をどんどんリリースする。テスト結果が “Green” なら常にリリースするようにしているチームもある。
Hermetic Builds (日本語でどう訳されてるんだ… 外部環境に依存しないビルド、みたいな感じかな?)
ビルド/リリースツールは一貫性があり、かつ何度でも実行できなければならない。複数人が同じコードを同時にビルドしたら、成果物は同じでなければならない。
ビルド結果はビルドマシン内のライブラリやソフトウェアには依存しない。ビルドは 特定のバージョンの コンパイラやライブラリに依存する。ビルドは self-contained であり、外部環境には左右されない。(要ディスカッション: たとえば Docker みたいなビルド環境を準備しておいて、そこの中でビルドが閉じている…みたいなことを言いたいのでは)
ビルドツール自身も閉じた環境でビルドしている。
Enforcement of Policies and Procedures
誰が何をできるかコントロールする。誰がコードを変更できるか、新しいリリースを作れるか… etc.
Continuous Build and Deployment
Google には Rapid という自動リリースシステムがある (ぐぐっても詳細が出てこない)。なんかすごいらしい。前述の4つの哲学 (Self-Service Model, High Velocity, etc.) を満足するためのツールらしい。
以下、ソフトウェア開発のライフサイクル @ Google。
Building
Blaze (OSS 版は Bazel) で Google のソフトウェアはビルドされる。Make, Gradle, Maven に類するもの。色んなプログラミング言語をビルド/テストするのに使える。Rapid の一部として組み込まれている。
Branching
コードは全て mainline (Git で言うところの master) にコミットされる。mainline からリリースブランチを切ってリリースする。リリースブランチへの変更を mainline に戻すことはない。バグ修正は mainline にコミットされ、リリースブランチに cherry-pick される。
(そもそもの開発時にどこにコミットする、みたいな話はなし)
Testing
mainline への変更にはテストが走る。
全てのテストが通ったビルドをリリースするのがオススメ (当然では…)。
リリースブランチをリリースするときにもテストを走らせる。全てのテストが通ったことを示すログを保存する。
テストには独立した環境を準備して、ビルド成果物に対してシステムレベルのチェックをする (これは具体的には何を言っているんだ…??)。テストは手動でも起動できるし、Rapid からも起動できる。
Packaging
Google には MPM (Midas Package Manager) という仕組みがあり、これを介してリリースが行われる。MPM は Blaze の成果物をパッケージにする。
# (英辞郎より)
Midas {名-1} : 《ギリシャ神話》ミダス◆欲張りな Phrygia の王。Dionysus によって、手に触れる物すべてが金になる褒美(苦悩?)を与えられる。
MPM パッケージにはラベルがつけられる。例えば dev や canary, production など。新しいパッケージを既存のラベルに適用すると、既存のラベルが示すパッケージが上書きされる。
(割と普通の仕組みだ)
Rapid
- Rapid は
Blueprintsというファイルで設定される。- DSL で記述される。テスト対象やデプロイ方法、プロジェクトオーナーなどが書かれる。
- Rapid で誰が何をできるかはロールベースの ACL で管理される。
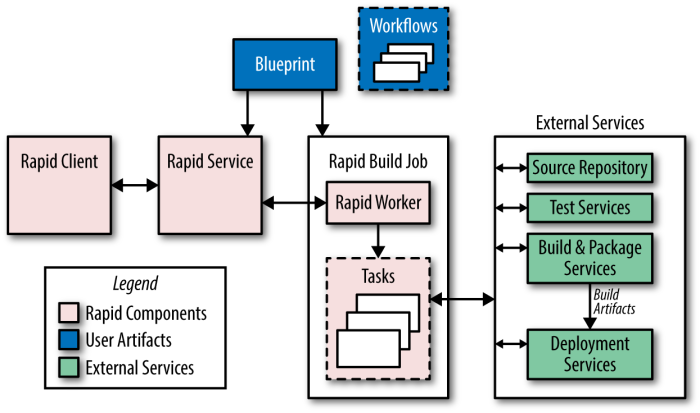
- Workflow には、リリース時に何をするかが記述される。
- Workflow は他の Workflow を起動できる。
Jenkins で例えると (だいたい):
- Rapid Client: GitHub Webhook / ユーザーのブラウザ
- Rapid Service: Jenkins サーバ
- Rapid Build Job: Jenkins ジョブ
- Tasks (実際には Borg のジョブ): Jenkins のタスク
典型的な Rapid のリリースプロセスは次のような感じ:
- 所定のリビジョンナンバーからリリースブランチを作成する。
Blazeでテストとビルドが並列で走る。これらは独立の環境で実行される。- ビルドの成果物が canary deployment 用に準備される。
- ここまでの処理内容がログとして記録される。
Deployment
Rapid で Borg のジョブに MPM の新しいパッケージ (Blueprint ファイルに記述された) を使うように指示してデプロイできる。
さらに込み入ったデプロイには Sisyphus を使う。 Sisyphus は SRE チームが開発した汎用的リリース自動化フレームワーク (Sisyphus もぐぐっても情報が出てこない)。 Python でデプロイメント手順を記述する (??)。
Sisyphus なら簡単なことから難しいことまで何でもできる。たとえば、クラスタ内の全てのジョブを一気に更新したり、数時間かけてゆっくり更新したりできる。なんなら数日間かけることもできる (それうれしいの?)。
Configuration Management
設定管理はリリースエンジニアと SRE が協調してがんばる領域だ。設定管理は簡単っぽくみえるけど、下手にやると不安定さの元凶になる。設定は SCM で管理し、変更にはコードレビューが課されるべきだ。
設定は mainline のモノを使おう…というのが初期の発想だった。これで、バイナリのリリースと設定変更を分離できた。ただし、これだとジョブを明示的に更新しないと設定変更が反映されないので、実行中のシステムと mainline の設定情報とが乖離することがあった。
MPM パッケージにバイナリと設定ファイルを詰め込もう…というのが次の発想だった。設定変更はデプロイ時にしかできないけど、デプロイそのものは単にパッケージを配布するだけに簡素化された。
設定ファイルも MPM パッケージにしよう…というのがさらに次の発想だった。たとえば、ある機能をフラグで on/off できるようにしておいて、実際の on/off は設定パッケージの種類で決まる、など。この場合、「ある機能を含むバイナリ」そのものは再起動する必要がない。
外部のデータストアから設定ファイルを読み込む方法もある。Chubby とか Bigtable に設定を置くこともある。
Conclusions
It’s Not Just for Googlers
(言っていることは分かるが、 Rapid の辺りは完全に Google べったりだろうよ)
Start Release Engineering at the Beginning
リリースエンジニアは後付で作られることが多いけど、それだと大変なので、早い内にそういうロールを考えましょう。
Chapter 9. Simplicity
(短いし思想的なことが主なので、さらっと)
ユーザーは増えるし、機能は追加されるし、ハードウェアは変わるし、安定して稼働するシステムを作るのは難しい。究極的には “agility” と “stability” のバランスを取ることが SRE の仕事だ。
System Stability Versus Agility
“agility” のために “stability” を犠牲にすることはままある。未知の領域を手探りでコーディングすることもある。そういうときには、挑戦して失敗することが問題を真に理解するために必要なステップだったりする。
プロダクションでは “agility” と “stability” のバランスが肝要である。SRE はシステムを安定させることに腐心しつつ、それが agility の低下につながらないようにする。実際には reliable さと agile さには相関がある。reliable なシステム (例えばビルド) がないと、agile に開発できないし。
The Virtue of Boring
退屈なシステムは素晴らしい。予期せぬタイミングで不思議なトラブルが起こるようなシステムは最悪だ。
essential complexity と accidental complexity は区別しましょう。essential complexity は本質的な複雑さ。accidental なのはエンジニアリングで排除できる複雑さ。たとえば、速く動作するウェブサーバーを書くのは essentially complex だ。Java で GC のインパクトを軽減させるのは accidental complexity を減らす仕事だ。 (わかりにくくないですか、この例…)
- SRE は accidental complexity が導入される変更は差し戻すべきだ。
- SRE は定期的に複雑さを削減していくべきだ。
I Won’t Give Up My Code!
エンジニアは人間なので、自分が書いたコードに対して執着がある (そうなの?)。
次のような判断は基本的に悪手。
- 後で必要になるかもしれないので、消すのではなくコメントアウトする。
- 今はいらないかもしれないけど、消すほどではないので feature flag でロジックが通らないようにする。
書かれたコードは全て負債だと思え。
The “Negative Lines of Code” Metric
新しい行や変更された行はバグをもたらす可能性がある。短いコードは理解しやすく、テストもしやすい。つまり、コードを消すのは素晴らしいことだ。
Minimal APIs
“perfection is finally attained not when there is no longer more to add, but when there is no longer anything to take away”
「足すものが何もない状態ではなく、削るものが何もない状態が最も美しい」的な。
Unix 哲学的な、ひとつのことをうまくやる API を作りましょう、というお話。
Modularity
これも Unix 哲学にしたがう感じの話。ひとつのことをうまくやる API は Modular であるべきで、他の API と組み合わせて使えるようにしましょう、というお話。
Modular なシステムであれば、バグ修正も局所的なリリースで直せる。
API の提供側は API をバージョニングするべき。そうでないと、API のクライアントにコードの変更を強いることになる。
データフォーマットも Modularity を意識すべき。Google の protobuf はシステム間のコミュニケーションを backward and forward compatible に行うためのフォーマット。
Release Simplicity
小さいリリースの方がインパクトも計測しやすい。小さい変更をどんどんリリースしよう。
A Simple Conclusion
Simple なモノは Reliable なモノである。
(SRE が) 機能追加に対して “No” と言うとき、それはイノベーションに反対しているわけではない。環境を Simple に保つことで、イノベーションを加速しているのだ。
ʅ(◞‿◟)ʃ
Chapter 10. Practical Alerting from Time-Series Data
(今回の輪読会の肝。さらっと嘘を書いている可能性あり。ご指摘お願いしたく。ただ、 Borgmon rules は真面目に読めたとしても、どうせ僕らが使えるものではないので、そこはゆるふわで)
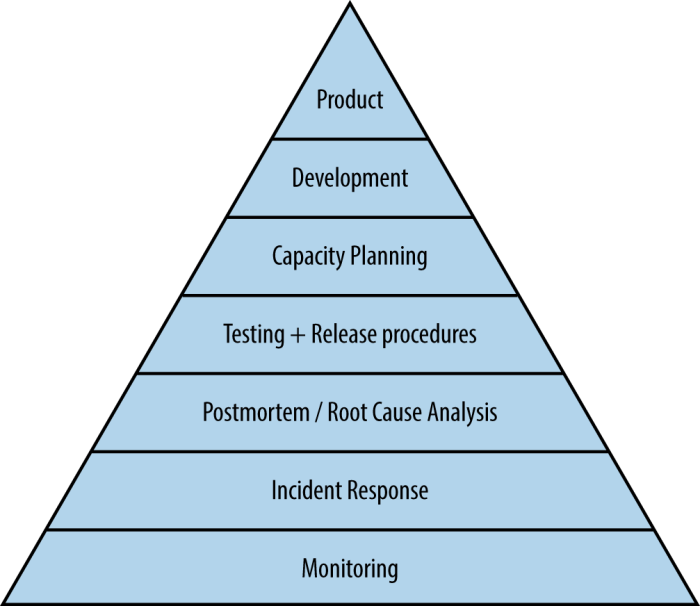
Monitoring は Hierarchy of Production Needs の最も基礎的なレイヤーである。
大規模システムのモニタが難しい理由はいくつかある。
- 単にモニタするコンポーネントが多すぎる。
- 適切にモニタリングすることで、システムを担当するエンジニアの負荷を下げる必要がある。
Google 規模だと、ひとつのマシンが不具合を起こしているくらいでアラートが鳴ると noisy 過ぎる。
大規模システムは個々のコンポーネントを管理するより、データをまとめあげて異常値 (outlier) を刈りとるべきである。
The Rise of Borgmon
2003 年に Borg ができて、割とすぐに Borgmon というモニタリングシステムが作られた。似たようなソフトウェアには Prometheus などがある。
(ほとんど Borg と Prometheus は同じもののようなので、Prometheus の典型的なシステムを掲載する)
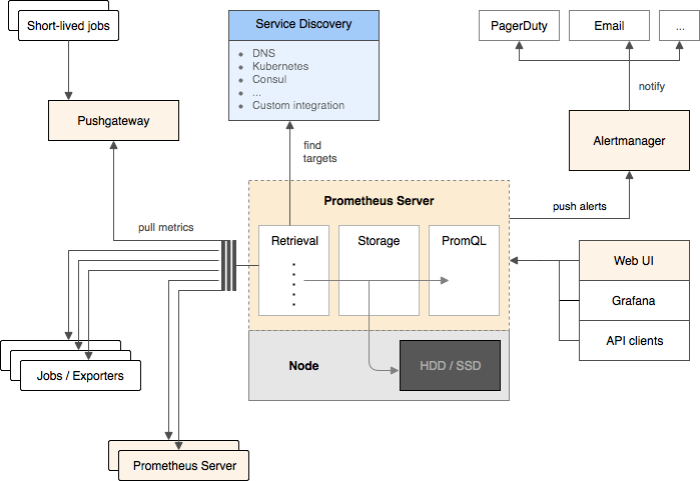
/varz エンドポイントを叩くとメトリクスが取れる。
% curl http://webserver:80/varz http_requests 37 errors_total 12
Borgmon は他の Borgmon からデータを取得できる。普通はクラスタごとに Borgmon を立てて、グローバルに Borgmon のペアを置く。
(クラスタと一言で表現しても、そのサイズはさまざまなのでは…)
Instrumentation of Applications / アプリケーションの計測一巡り
/varz が plain text でスペース区切りのメトリクスを出力する (前述のやつ)。後の拡張で、ひとつの変数に対して複数のラベルをつけて出力できるようになった。例えば、 HTTP 200 が 25 件で、500 が 12 件の map-valued な値は次のような感じになる。
http_responses map:code 200:25 404:0 500:12
スキーマレスなので、新しいメトリクスを追加するのも簡単で便利 (それだけだと JSON とかでも同じでは?)。
Collection of Exported Data
Borgmon は監視対象の発見に Service Discovery のツールを使う (DNS [BNS] や Consul など)。
Borgmon は一定間隔ごとに /varz を叩いて、結果をメモリに貯める。結果はピアにも共有される。
Borgmon は監視対象ごとに “synthetic (作り物)” な情報も記録する。例えば名前解決が成功したか、いつデータを取得したか、などの情報。
/varz のアプローチは SNMP のような「極力ネットワークを使わないようにする」考え方と違う。HTTP のオーバーヘッドが問題になるケースはほとんどないし、そもそも Borgmon はメトリクスが取れないことそのものを signal として使うことができる。
Storage in the Time-Series Arena
Borgmon は (timestamp, value) の組みでデータを保存する。この形式を time-series と言う。各々の time-series はユニークにラベル (name=value の形式) 付される。
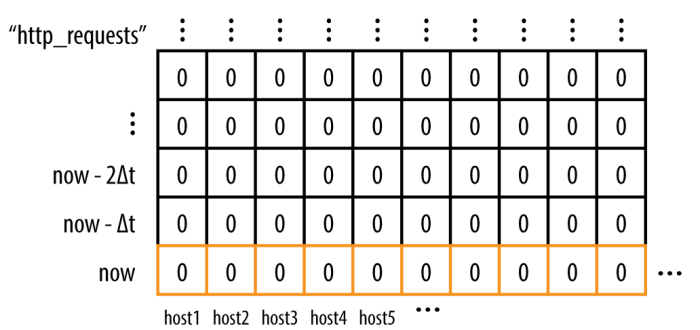
メモリの内容は定期的に TSDB (Time-Series Database) 形式でディスクに Sync される。少し遅くなるけど、Borgmon は TSDB に対してクエリを投げることができる。
Labels and Vectors

time-series の名前は labelset である。なぜなら、これは key=value のラベルのセットで表現されるから。TSDB でひとつの time-series をユニークに探すためには、次のラベルは必須である。
- var: 変数名
- job: モニタ対象のサーバー (アプリ) の種類
- service: 雑に言うとジョブの集合を表すもの
- zone: Borgmon が所属するデータセンタの名前
これらをまとめて、variable expression として表現できる。
{var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west}
こういう variable expression で labelset がマッチする全ての time-series をベクタ形式で取得できる。たとえば、先ほどの expression から instance ラベルを外すと (クラスタ内に複数のインスタンスがあれば) 各々のインスタンスでの最新の http_requests の数がベクタで取得できる。
{var=http_requests,job=webserver,service=web,zone=us-west}
の結果:
{var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west} 10
{var=http_requests,job=webserver,instance=host1:80,service=web,zone=us-west} 9
{var=http_requests,job=webserver,instance=host2:80,service=web,zone=us-west} 11
{var=http_requests,job=webserver,instance=host3:80,service=web,zone=us-west} 0
{var=http_requests,job=webserver,instance=host4:80,service=web,zone=us-west} 10
期間を指定した time-series のクエリも可能である (variable expression と言ったり query と言ったりしているけど、これらは同じものを指しているのか?)。
{var=http_requests,job=webserver,service=web,zone=us-west}[10m]
ここの [10m] は “直近10分間” を表現する。もしデータを毎分で収集しているのであれば、次のような出力が得られるはず。
{var=http_requests,job=webserver,instance=host0:80, ...} 0 1 2 3 4 5 6 7 8 9 10
{var=http_requests,job=webserver,instance=host1:80, ...} 0 1 2 3 4 4 5 6 7 8 9
{var=http_requests,job=webserver,instance=host2:80, ...} 0 1 2 3 5 6 7 8 9 9 11
{var=http_requests,job=webserver,instance=host3:80, ...} 0 0 0 0 0 0 0 0 0 0 0
{var=http_requests,job=webserver,instance=host4:80, ...} 0 1 2 3 4 5 6 7 8 9 10
Rule Evaluation
Borgmon は単なる programable calculator である。Borgmon プログラミングは Borgmon rules で行う。これを使い代数表現で、ある time-series から別な time-series を作る。
Borgmon rules は可能な限り並列に評価される。後ろの評価が前の評価結果に依存する場合なんかは無理。評価結果として返るベクタのサイズなども実行時間を決める要素のひとつ。実行時間がかかるときは、いい CPU で Borgmon を動かせばいい。
(rate と ratio が英語版だと可換ではなくて、この書籍の文脈の rate は “時間” を表現しているようだ。でも Borgmon rules の rate() は比率を出してくれているような?)
(Borgmon にはかぎらないけど) モニタにはカウンターとゲージがある。カウンターは増加だけする。たとえば通算アクセス数など。計測インターバル中のデータがロスしないように、カウンターを使うのがオススメ。
次の Borgmon rules をどう評価するか…。
rules <<<
# Compute the rate of requests for each task from the count of requests
{var=task:http_requests:rate10m,job=webserver} =
rate({var=http_requests,job=webserver}[10m]);
# (前の評価結果に依存している)
# Sum the rates to get the aggregate rate of queries for the cluster;
# ‘without instance’ instructs Borgmon to remove the instance label
# from the right hand side.
{var=dc:http_requests:rate10m,job=webserver} =
sum without instance({var=task:http_requests:rate10m,job=webserver})
>>>
このとき、 task:http_requests:rate10m は次のような感じ:
{var=task:http_requests:rate10m,job=webserver,instance=host0:80, ...} 1
{var=task:http_requests:rate10m,job=webserver,instance=host1:80, ...} 0.9
{var=task:http_requests:rate10m,job=webserver,instance=host2:80, ...} 1.1
{var=task:http_requests:rate10m,job=webserver,instance=host3:80, ...} 0
{var=task:http_requests:rate10m,job=webserver,instance=host4:80, ...} 1
dc:http_requests:rate10m はこんな感じ:
{var=dc:http_requests:rate10m,job=webserver,service=web,zone=us-west} 4
dc:http_requests:rate10m みたいな名前づけは Google の convention で、それぞれ “aggregation level”, “the variable name” そして “the operation that created that name” を表現する。
じゃあ、これはどう読む?
rules <<<
# Compute a rate per task and per ‘code’ label
{var=task:http_responses:rate10m,job=webserver} =
rate by code({var=http_responses,job=webserver}[10m]);
# Compute a cluster level response rate per ‘code’ label
{var=dc:http_responses:rate10m,job=webserver} =
sum without instance({var=task:http_responses:rate10m,job=webserver});
# Compute a new cluster level rate summing all non 200 codes
{var=dc:http_errors:rate10m,job=webserver} =
sum without code({var=dc:http_responses:rate10m,job=webserver,code=!/200/});
# Compute the ratio of the rate of errors to the rate of requests
{var=dc:http_errors:ratio_rate10m,job=webserver} =
{var=dc:http_errors:rate10m,job=webserver}
/
{var=dc:http_requests:rate10m,job=webserver}; # これ typo じゃないの? `http_requests` ではなく `http_responses` では?
>>>
{var=task:http_responses:rate10m,job=webserver} はこんな感じの出力になる:
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host0:80, ...} 1
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host0:80, ...} 0
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host1:80, ...} 0.5
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host1:80, ...} 0.4
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host2:80, ...} 1
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host2:80, ...} 0.1
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host3:80, ...} 0
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host3:80, ...} 0
{var=task:http_responses:rate10m,job=webserver,code=200,instance=host4:80, ...} 0.9
{var=task:http_responses:rate10m,job=webserver,code=500,instance=host4:80, ...} 0.1
{var=dc:http_responses:rate10m,job=webserver} はこんな感じ:
{var=dc:http_responses:rate10m,job=webserver,code=200, ...} 3.4
{var=dc:http_responses:rate10m,job=webserver,code=500, ...} 0.6
そんで {var=dc:http_responses:rate10m,job=webserver,code=!/200/} はこんな感じ:
{var=dc:http_responses:rate10m,job=webserver,code=500, ...} 0.6
{var=dc:http_errors:rate10m,job=webserver} は…:
{var=dc:http_errors:rate10m,job=webserver, ...} 0.6
{var=dc:http_errors:ratio_rate10m,job=webserver} は:
{var=dc:http_errors:ratio_rate10m,job=webserver} 0.15
になる (そうなの?)。
Borgmon rules は新しい time-series を作るので on-call のときに読めるし、便利そうなら permanent にコンソールで表示することもできる。
Alerting
10分間のエラー率が1%以上で、1秒に1回以上のエラーが (2分以上) 出るときにアラートをあげる rule:
rules <<<
{var=dc:http_errors:ratio_rate10m,job=webserver} > 0.01
and by job, error
{var=dc:http_errors:rate10m,job=webserver} > 1
for 2m
=> ErrorRatioTooHigh
details "webserver error ratio at %trigger_value%"
labels { severity=page };
>>>
Borgmon は Alertmanager と接続している。これは Alert RPC を受け取ると alert notification を送信する。 Alertmanager で設定できる機能はこんな感じ:
- 他のアラートが active なときには別なアラートを active にしない。
- 同じラベルセットを持つ複数のアラートはひとつにまとめあげる。
- 似たようなラベルセットのアラートが発火したときに fan-out したり fan-in したり。
Sharding the Monitoring Topology
Borgmon は別な Borgmon から time-series をインポートできる。Region ごとに Borgmon で監視対象の time-series を取得して、最終的に global な Borgmon が各 region の Borgmon から time-series を取得する。それが Google のジャスティス。
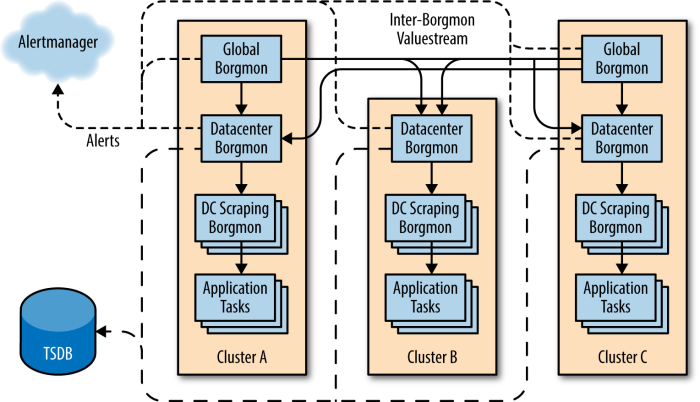
Black-Box Monitoring
Prometheus は White-Box Monitoring だけど、これだけだとユーザーにインパクトがあるメトリクスはとれない。Black-Box Monitoring も組み合わせましょう。
Prober が Black-Box のための機能で、監視対象に特定のプロトコル (たとえば HTTP) でリクエストを投げて結果が success かどうかを調べる。失敗したら Alertmanager に通知をしてアラートを投げる。(つまりは Runscope みたいな機能かな)
なお prober は Prometheus にもある概念。
Maintaining the Configuration
Borgmon では複数のモニタ対象に同じ Borgmon rules を適用できる。同じような設定をモニタ対象ごとに何度も書き直す必要はない。
Borgmon には language templates というマクロ的な機能もある (しかし具体的にどう機能するか分からず)。これを使い、似通った rule はライブラリ化できる。
人工的な time-series をつかい、rule をテストすることもできる。(これが必要になるということは、rule は複雑になりかねない…ということですよね)
Ten Years On…
Borgmon のおかげで、スケールする管理システムが実現できましたよ、的な話。 check-and-alert な仕組みだとスケールしないですよ、と。
サービス規模のスケールに対してモニタリングのコストのスケールは sublinear であるべきだよ、と。
Borgmon の話ばっかりしていたけど、Prometheus や Riemann、Heka や Bosun 辺りはコンセプトの似た OSS なので、そういうのを調べてみるのもいいかもね、と。
